
SWE-Next
Collection
SWE-Next turns real repository changes into self-verifying software engineering tasks and reusable execution environments for scalable agent training • 7 items • Updated
SWE-Next-7B is a repository-level software engineering agent fine-tuned from Qwen/Qwen2.5-Coder-7B-Instruct on the released SWE-Next SFT Trajectories. The model is trained with full-parameter supervised fine-tuning on execution-grounded trajectories collected from real merged pull requests and validated repository environments.
SWE-Next introduces reusable repo-quarter profiles, which reuse the same environment across nearby commits in time while keeping each task run separate and reproducible. Using only 30 hours and 639GB of environment storage, SWE-Next processes 3,971 seed repositories and 102,582 candidate commit pairs mined from real merged PRs to construct a dataset of 2,308 self-verifying instances. SWE-Next improves downstream pass@1 on SWE-Bench Verified and SWE-Bench Lite with fewer or comparable training trajectories, making large-scale executable data collection far more practical and accessible for research.
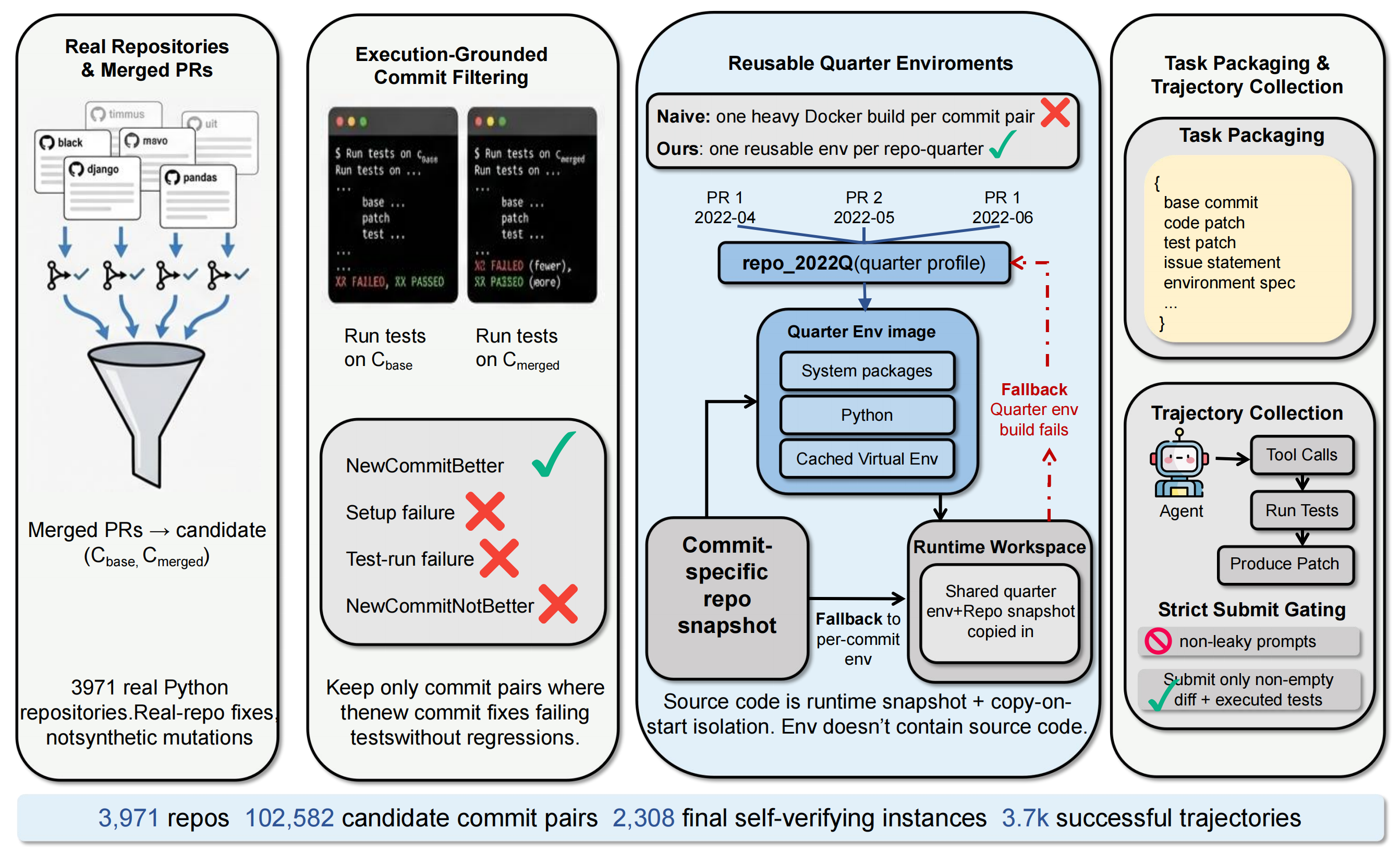
This model is trained on 3,693 selected SFT trajectories derived from the SWE-Next collection. The training data emphasizes clean repository-level repair traces and recovery-style debugging trajectories rather than isolated code-completion examples.
Training recipe summary:
Qwen/Qwen2.5-Coder-7B-InstructTIGER-Lab/SWE-Next-SFT-TrajectoriesFor full usage details, please refer to the official SWE-Next GitHub repository. The repository provides the complete setup and evaluation workflow for released models, including:
In particular, the GitHub repo contains the exact commands used to serve SWE-Next-7B and evaluate it on SWE-Bench-style tasks under the SWE-Next execution interface.
This repo contains the released 7B model checkpoint. Related artifacts are available separately:
TIGER-Lab/SWE-NextTIGER-Lab/SWE-Next-SFT-TrajectoriesTIGER-Lab/SWE-Next-14Bgithub.com/TIGER-AI-Lab/SWE-Next@misc{liang2026swenextscalablerealworldsoftware,
title={SWE-Next: Scalable Real-World Software Engineering Tasks for Agents},
author={Jiarong Liang and Zhiheng Lyu and Zijie Liu and Xiangchao Chen and Ping Nie and Kai Zou and Wenhu Chen},
year={2026},
eprint={2603.20691},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2603.20691},
}