 +
+| Baidu Yun | Google Cloud | Peking University Yun | +|
|---|---|---|---|
| DATA | Link | Link | Link | +
| ANNOTATION | Link | Link | Link | +
+ ![]() +
+
+
+
+
+> [**Video-LLaVA: Learning United Visual Representation by Alignment Before Projection**](https://arxiv.org/abs/2311.10122)
+> Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan
+[](https://github.com/PKU-YuanGroup/Video-LLaVA) [](https://github.com/PKU-YuanGroup/Video-LLaVA) [](https://arxiv.org/abs/2311.10122)
+
+> [**MoE-LLaVA: Mixture of Experts for Large Vision-Language Models**](https://github.com/PKU-YuanGroup/MoE-LLaVA/blob/main/MoE-LLaVA.pdf)
+> Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Junwu Zhang, Munan Ning, Li Yuan
+[](https://github.com/PKU-YuanGroup/MoE-LLaVA) [](https://github.com/PKU-YuanGroup/MoE-LLaVA) [](https://arxiv.org/abs/2401.15947)
+
+> [**Video-Bench: A Comprehensive Benchmark and Toolkit for Evaluating Video-based Large Language Models**](https://arxiv.org/abs/2311.08046)
+> Munan Ning, Bin Zhu, Yujia Xie, Bin Lin, Jiaxi Cui, Lu Yuan, Dongdong Chen, Li Yuan
+[](https://github.com/PKU-YuanGroup/Video-Bench) [](https://github.com/PKU-YuanGroup/Video-Bench) [](https://arxiv.org/abs/2311.16103)
+
+
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
| Modality | LoRA tuning | Fine-tuning | +
|---|---|---|
| Video | LanguageBind_Video | LanguageBind_Video_FT | +
| Audio | LanguageBind_Audio | LanguageBind_Audio_FT | +
| Depth | LanguageBind_Depth | - | +
| Thermal | LanguageBind_Thermal | - | +
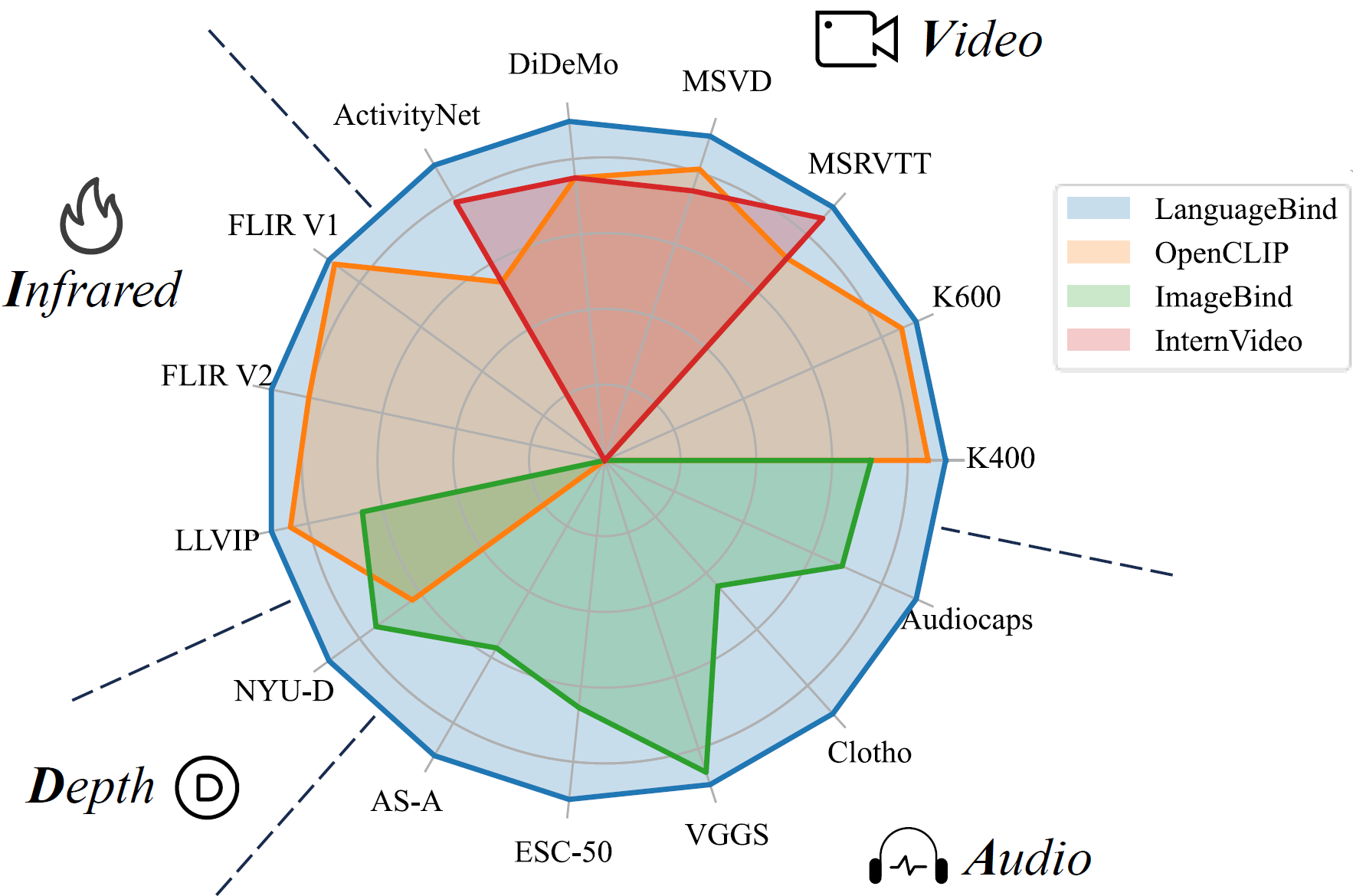
| Version | Tuning | Model size | Num_frames | HF Link | MSR-VTT | DiDeMo | ActivityNet | MSVD | +
|---|---|---|---|---|---|---|---|---|
| LanguageBind_Video | LoRA | Large | 8 | Link | 42.6 | 37.8 | 35.1 | 52.2 | +
| LanguageBind_Video_FT | Full-tuning | Large | 8 | Link | 42.7 | 38.1 | 36.9 | 53.5 | +
| LanguageBind_Video_V1.5_FT | Full-tuning | Large | 8 | Link | 42.8 | 39.7 | 38.4 | 54.1 | +
| LanguageBind_Video_V1.5_FT | Full-tuning | Large | 12 | Coming soon | +||||
| LanguageBind_Video_Huge_V1.5_FT | Full-tuning | Huge | 8 | Link | 44.8 | 39.9 | 41.0 | 53.7 | +
| LanguageBind_Video_Huge_V1.5_FT | Full-tuning | Huge | 12 | Coming soon | +
| Cache of pretrained weight | Baidu Yun | Google Cloud | Peking University Yun | +
|---|---|---|---|
| Large | Link | Link | Link | +
| Huge | Link | - | Link | +
| Datasets | Baidu Yun | Google Cloud | Peking University Yun | +
|---|---|---|---|
| LLVIP | Link | Link | Link | +
| FLIR V1 | Link | Link | Link | +
| FLIR V2 | Link | Link | Link | +
 +
+  +
+  +
+